Results from the ML model training on two features vs all features, O(Λ^{-4})
Results from the ML model training on two features vs all features, \(O(Λ^{-4})\)#
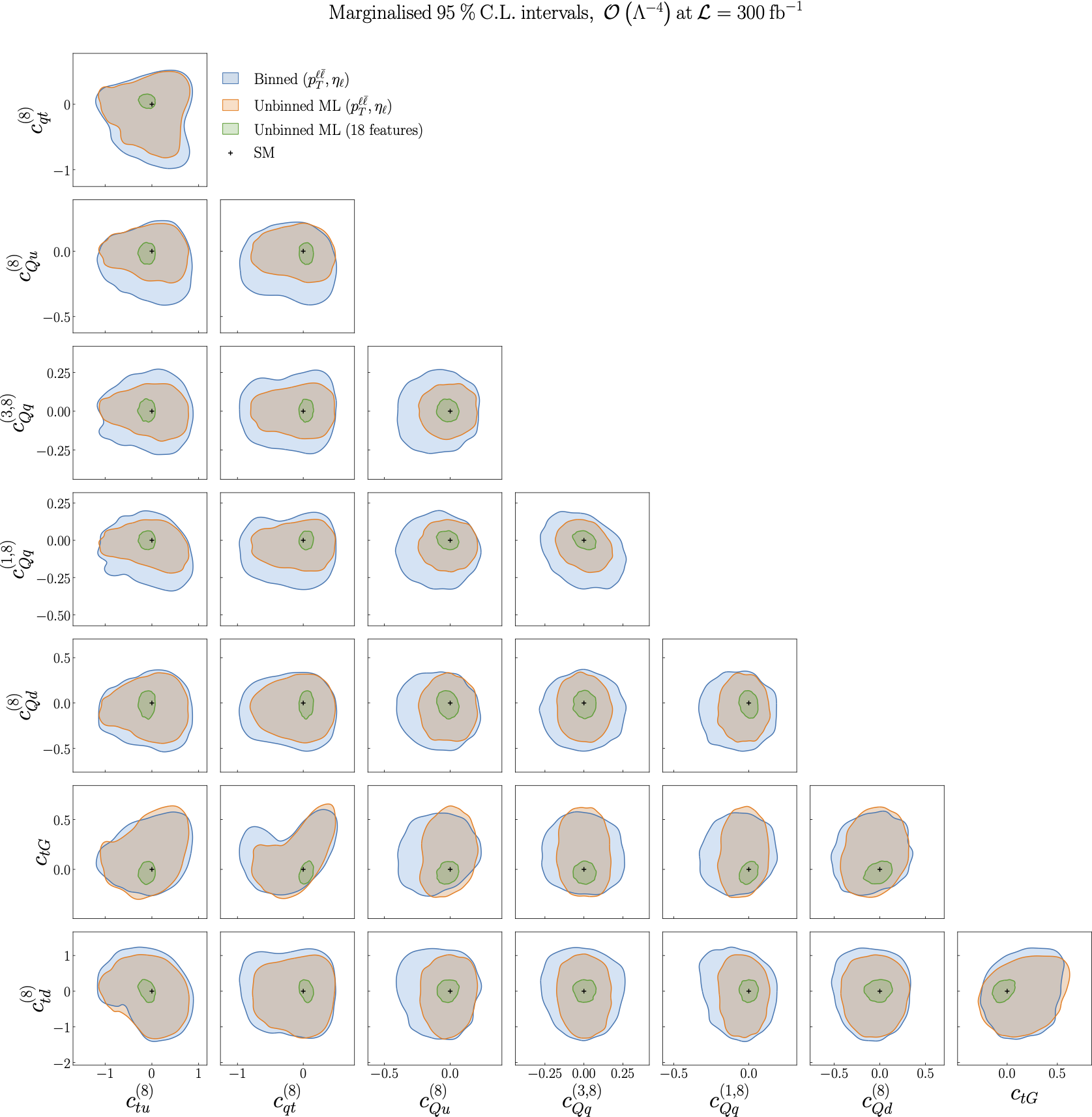
Figure 5.5 of [Gomez Ambrosio et al., 2022].
Following from the previous results, we now present a comparison of the results obtained by means of the ML model when only (\(p_{\ell \ell}\), \(\eta_{\ell}\)) are used for the training vs when the full set of \(n_{k} = 18\) kinematic features is used. We observe a marked improvement in the constraints obtained on each SMEFT operator when all kinematic features are used.
These constraints are also compared to those obtained from a binned analysis of (\(p_{\ell \ell}\), \(\eta_{\ell}\)), shown in blue, and again we see an improvement when using the ML model.