Results from the ML model vs binning in two features, O(\Lambda^{-2})
Results from the ML model vs binning in two features, \(O(\Lambda^{-2})\)#
Figure 5.2 of [Gomez Ambrosio et al., 2022].
95% CL intervals on \(n_{eft}=5\) Wilson coefficients relevant for the description of top quark pair production at the linear \(O(\Lambda^{-2})\) level.
The black cross indicates the SM values used to generate the pseudo-data. We present marginalised intervals, obtained from the full posterior distribution provided by Nested Sampling.
We compare the constraints obtained from the ML model trained on two features, \(p_{\ell \ell}\) and \(\eta_{\ell}\), with those obtained from a binned analysis of the same features.
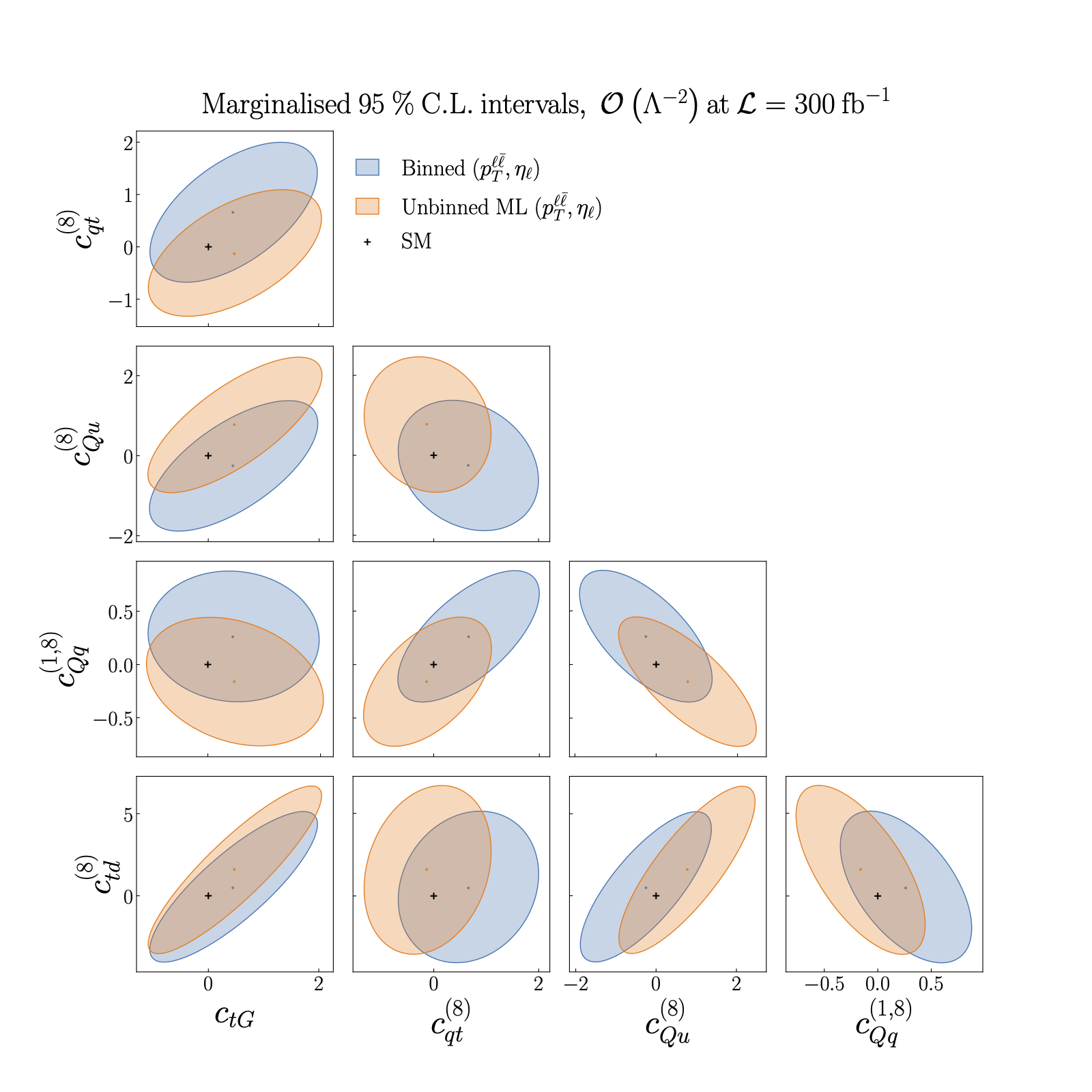
See also the next page for the comparison of this ML model with the ML model trained on the full set of \(n_{k} = 18\) kinematic features.
Note that we do not constrain the coefficients \(C_{Qd}^{(8)}\), \(C_{Qq}^{3,8}\) or \(C_{tu}^{(8)}\) here, due to their approximate degeneracies with the coefficients \(C_{Qu}^{(8)}\), \(C_{Qq}^{1,8}\) and \(C_{td}^{(8)}\) respectively at the linear order, [Brivio et al., 2020].